REVERIE Dataset
REVERIE is a large-scale remote object grounding dataset introduced in REVERIE: Remote Embodied Visual Referring Expression in Real Indoor Environments (CVPR 2020). It comprises 10,318 panoramas within 86 buildings containing 4,140 target objects, and 21,702 crowd-sourced instructions with an average length of 18 words. The table below shows sample instructions from our dataset, which illustrate various linguistic phenomena, such as spatial relations, dangling modifiers, and coreferences
| 1. Fold the towel in the bathroom with the fishing theme. |
| 2. Enter the bedroom with the letter E over the bed and turn the light switch off. |
| 3. Go to the blue family room and bring the framed picture of a person on a horse at the top left corner above the TV. |
| 4. Push in the bar chair, in the kitchen, by the oven. |
| 5. Windex the mirror above the sink, in the bedroom with the large, stone fireplace. |
| 6. Could you please dust the light above the toilet in the bathroom that is near the entry way? |
| 7. At the top of the stairs, the first set of potted flowers in front of the stairs need to be dusted off. |
| 8. To the right at the end of the hall, where the large blue table foot stool is, there is a mirror that needs to be wiped. |
| 9. Go to the hallway area where there are three pictures side by side and get me the one on the right. |
| 10. There is a bottle in the office alcove next to the piano. It is on the shelf above the sink on the extreme right. Please bring it here. |
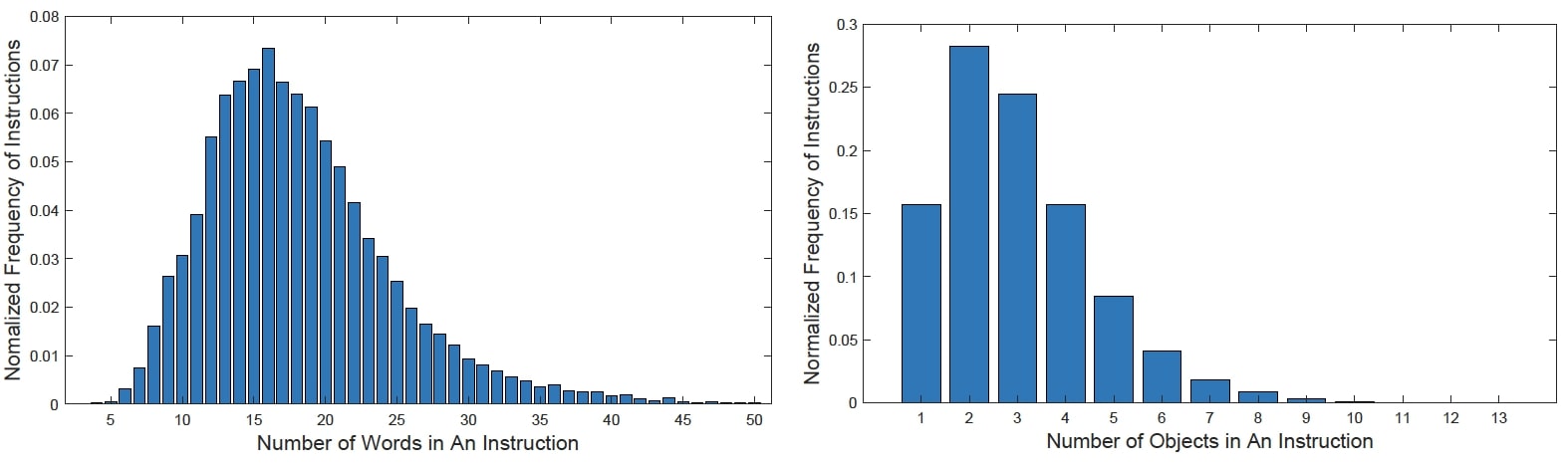
Data Distribution The left figure below displays the length distribution of the collected instructions, which shows that most instructions have 10~22 words while the shortest annotation could be only 3 words, such as 'Flush the toilet'. It also shows that 56% instructions mention 3 or more objects, 28% instructions mention 2 objects, and the remaining 15% instructions mention 1 object. The right figure below presents the relative amount of words used in instructions and the target object categories in the form of word cloud. It shows that people prefer 'go' for navigation, and most instructions involve 'bathroom'. There are 4,140 target objects in the dataset, falling into 489 categories, which are 6 times more than the 80 categories in ReferCOCO, a most popular referring expression dataset at present.

Data Splits We follow the same train/val/test split strategy as the R2R datasets. The training set consists of 60 scenes and 10,466 instructions over 2,353 objects. The validation set including seen and unseen splits totally contains 56 scenes, 953 objects, and 4,944 instructions, of which 10 scenes and 3,521 instructions over 513 objects are reserved for val unseen split. For the test set, we collect 6,292 instructions involving 834 objects randomly scattered in 16 scenes. All the test data are unseen during training and validation procedures.